In regression problems we are given samples of a set of independent (predictor) variables x1, x2, …, xn , and the value of the respective dependent (output) variable y. Our goal is to obtain a model that captures the mapping y = ƒ( x1, x2, …, xn) based on the given samples. Classification differs from this setup in that y is a discrete variable instead of continuous one.
Mapping regression into classification can be seen as a kind of pre-processing technique that enables the use of classification algorithms on regression problems. Our method starts by creating a data set with discrete target variable values. This step involves examining the original continuous values of the target variable and suitably dividing them into a series of intervals. Every example whose output variable value lies within the boundaries of an interval will be assigned the respective "discrete class"[1].
Grouping the range of observed continuous values of the target variable into a set of intervals involves two main decisions : how many intervals to create; and how to choose the interval boundaries. As for this later issue we use three methods that for a given a set of continuous values and the number of intervals return their defining boundaries :
· Equally probable intervals (EP): This creates a set of N intervals with the same number of elements.
· Equal width intervals (EW): The original range of values is divided into N intervals with equal width.
· K-means clustering (KM): In this method the aim is to build N intervals that minimize the sum of the distances of each element of an interval to its gravity center (Dillon & Goldstein, 1984). This method starts with the EW approximation and then moves the elements of each interval to contiguous intervals whenever these changes reduce the referred sum of distances.
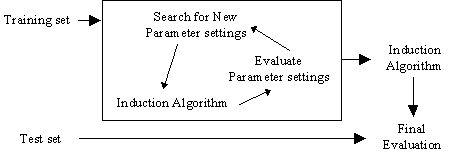
The number of intervals used (i.e. the number of classes) will have a direct effect on the accuracy of the subsequent learned theory. This means that they can be seen as a parameter of the learning algorithm. Our goal is to set the value of this "parameter" such that the system performance is optimized. As the number of possible ways of dividing a set of continuous values into a set of intervals is potentially infinite a search algorithm is necessary. The wrapper approach (John et al., 1994; Kohavi, 1995) is a well known strategy has been mainly used for feature subset selection (John et al., 1994) and parameter estimation (Kohavi, 1995). The use of this iterative approach to estimate a parameter of a learning algorithm can be described by the following figure:
· Varying the number of intervals (VNI): This simple alternative consists of incrementing the previously tried number of intervals by a constant value.
· Incrementally improving the number of intervals (INI) : The idea of this alternative is to try to improve the previous set of intervals taking into account their individual evaluation. The next set of intervals is built using the median of these individual error estimates. All intervals whose error is above the median are further split by dividing them in two. All the other intervals remain unchanged.
These two alternatives together with the three given splitting strategies make six alternative discretization methods which can be tuned to the given task using a wrapper approach. The RECLA system allows the user to explicitly select one of these methods. If this is not done the system automatically selects the one that gives better estimated results.
The other important component of the wrapper approach is the evaluation strategy. We use a N-fold Cross Validation (Stone, 1974) estimation technique which is well-known for its reliable estimates of prediction error. This means that each time a new tentative set of intervals is generated RECLA uses an internal N-fold Cross Validation (CV) process to evaluate it. In the next subsection we provide a small example of a discretization process to better illustrate our search-based approach.