Sistemas de Operação
Trabalho Prático 3: Sistema de Gestão de Ficheiros

Em traços gerais, o trabalho consiste no desenvolvimento de uma aplicação capaz de emular um sistema (simplificado) de gestão de ficheiros em UNIX. Mais concretamente, inclui o desenho da estrutura de dados para organização do sistema de ficheiros, a implementação de rotinas de I/O para acesso ao mesmo, e a implementação de um conjunto de utilitários de mais alto-nível para manipulação de ficheiros e directórios.
O trabalho está estruturado por etapas para simplificar a sua execução.
Nesta 1ª etapa pretende-se que desenhe o conjunto das estruturas de dados de suporte à organização do sistema de ficheiros e que implemente um procedimento format que permita definir e formatar novos sistemas. Para tal, considere a organização que se segue:
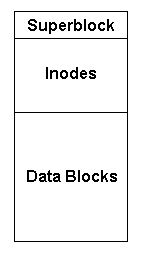
O sistema de ficheiros pode ser visto como um conjunto contíguo de blocos de disco em que se destacam três regiões principais: o superblock (a que corresponde o bloco 0), a região dos inodes (a que correspondem os blocos seguintes, começando no 1), e a região para dados propriamente dita (a que correspondem os restantes blocos).
typedef struct superblock_entry {
int check_number; /* número que permite identificar o sistema de ficheiros como válido */
int block_size /* tamanho de cada bloco do sistema {1, 2, 4(default) ou 8 Kbytes} */
int free_block; /* o número do primeiro bloco da lista de blocos de dados não utilizados */
int num_inodes; /* o número de inodes no sistema de ficheiros */
int root_inode; /* o numero do inode a que corresponde o directório root */
int free_inode; /* o número do primeiro inode da lista de inodes não utilizados */
} superblock;
#define N_DIRECT_BLOCKS 12
#define TYPE_FREE 0
#define TYPE_FILE 1
#define TYPE_DIR 2
typedef struct inode_entry {
int number; /* o número do inode */
int type; /* o tipo do inode {TYPE_FILE, TYPE_DIR, TYPE_FREE} */
int size_free; /* tamanho do ficheiro(TYPE_FILE)/directório(TYPE_DIR) em bytes
ou próximo inode não utilizado(TYPE_FREE) */
int direct_block[N_DIRECT_BLOCKS]; /* índices dos blocos onde estão guardados os dados */
int indirect_block; /* índice do bloco de índices para outros blocos
(para ficheiros maiores que N_DIRECT_BLOCKS*BLOCK_SIZE bytes) */
} inode;
Os inodes são numerados de 0 até num_inodes-1.
Através do valor de free_inode é possível aceder ao primeiro inode não
utilizado. Para percorrer a lista completa dos inodes não utilizados
deve seguir-se a referência size_free do inode anterior. Um
valor de -1 em size_free marca o fim da lista.
A emulação dos sistemas de ficheiros será feita sobre ficheiros comuns estruturados segundo a organização descrita. Sendo assim, ao iniciar o emulador do sistema de gestão de ficheiros (sugestão de nome: virtual_fs) deverá indicar como argumento o ficheiro sobre o qual o emulador deverá funcionar. Exemplo: virtual_fs discoC. Se o ficheiro não corresponder a um sistema de ficheiros válido (verificar o check_number e o block_size do superblock) deve ser reportado um erro e o emulador deve terminar. Para iniciar um novo sistema de ficheiros, deverá indicar o nome de um novo ficheiro seguido da informação relativa ao tamanho de cada BLOCK_SIZE (opção -b seguido do tamanho em Kbytes: 1, 2, 4 ou 8) e ao tamanho mínimo do sistema de ficheiros (opção -s seguido do tamanho em Kbytes). Exemplo: virtual_fs -b2 -s2000 discoC. Como 2000 Kbytes não é um tamanho válido para um sistema de ficheiros com blocos de 2 Kbytes, já que não existe nenhum N tal que 2*(1+(32+1)*N) seja igual a 2000, esse tamanho deve ser arredondado para o primeiro N que resulte num valor maior que 2000. Para o exemplo em causa, o tamanho do novo sistema de ficheiros deveria ser 2048 Kbytes, já que para N = 30, 2*(1+33*N) é igual a 1982, e para N = 31, 2*(1+33*N) é igual a 2048.
Use o protótipo que se segue para o procedimento que permite formatar e iniciar todas as estruturas de dados de novos sistemas:
void my_format(int fd, int block_size, int filesystem_size);
Um ficheiro não é nada mais do que um conjunto de blocos de dados que podem ser escritos e lidos. Cada ficheiro corresponde a um inode que especifica quais os blocos de dados utilizados pelo ficheiro. A ordem dos blocos no ficheiro é a ordem representada no inode. Quando o tamanho do ficheiro excede N_DIRECT_BLOCKS blocos de dados, utiliza-se um bloco de dados auxiliar para representar os restantes blocos de dados necessários para o ficheiro. O campo indirect_block da estrutura dos inodes guarda o índice do bloco de índices para outros blocos.
A implementação de directórios é de certa forma idêntica à dos ficheiros, a diferença reside no facto dos blocos de dados para directórios seguirem um formato predefinido. Um bloco de dados para um directório, pode ser visto como um array de estruturas de dados do seguinte tipo:
#define MAX_NAME_LENGHT 28
typedef struct directory_entry {
int inode; /* inode associado ao ficheiro/subdirectório */
char name[MAX_NAME_LENGHT]; /* nome do ficheiro/subdirectório */
} dir_entry;
Cada uma destas estruturas corresponde a um ficheiro/subdirectório do
directório em causa. O campo name guarda o nome do ficheiro/subdirectório,
enquanto o campo inode guarda a referência do inode que representa
o ficheiro/subdirectório.
Nesta etapa, pretende-se que implemente os utilitários para manipulação de directórios. Segue-se uma breve descrição de cada um deles:
Note que a criação de um novo directório, implica desde logo, a criação de duas entradas, uma para o directório corrente "." e outra para o directório pai "..". O inode associado ao directório root "/" é definido pelo campo root_inode do superblock. Para todos os utilitários, considere apenas os casos em que o argumento dir é o directório corrente (.), o directório pai (..), ou um subdirectório do directório actual. Para todos os outros casos, reporte um erro apropriado (ou seja, não considere o uso de caminhos como my_dir_1/.../my_dir_n/my_fich).
Nesta etapa pretende-se que implemente um procedimento defrag que permita desfragmentar o sistema de ficheiros. O procedimento deve reorganizar o conjunto de blocos de dados por forma a garantir que os ficheiros e subdirectórios de um dado directório e que cada ficheiro ou subdirectório particular, fiquem representados em blocos de dados contíguos. O procedimento deve imprimir uma listagem dos blocos de dados utilizados por cada um dos ficheiros/directórios antes e depois de executar o processo de desfragmentação do sistema de ficheiros.