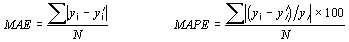 (1)
(1)Classification systems search for theories that have minimal estimated prediction error according to a 0/1 loss function, thus making all errors equally important. In regression, prediction error is a function of the difference between the observed and predicted values (i.e. errors are metric). Accuracy in regression is dependent on the amplitude of the error. In our experiments we use the Mean Absolute Error (MAE) and the Mean Absolute Percentage Error (MAPE) as regression accuracy measures :
(1)
In order to differentiate among different errors our method incorporates misclassification costs in the prediction procedure. If we take ci,j as the cost of classifying a class j instance as being class i, and if we take p(j|X) as the probability given by our classifier that instance X is of class j, we can take the task of classifying instance X as finding the class i that minimizes the expression
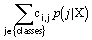 (2)
(2)
Here we associate classes with intervals and we take as class labels the intervals medians. In our methodology we propose to estimate the cost of misclassifying two intervals by using the absolute difference between their representatives, i.e.
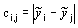 (3)
(3)
where
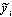 is the median of the values that where "discretized" into the interval
i.
is the median of the values that where "discretized" into the interval
i.
By proceeding this way we ensure that the system predictions minimize the expected absolute distance between the predicted and observed values.