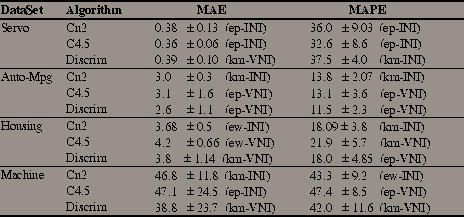
Table 4 - Best results of Classification algorithms using RECLA.
We have carried out several experiments with four real world domains. These data sets were obtained from the UCI machine learning repository (Merz & Murphy, 1996). Some of the characteristics of the data sets used are summarized in Table 3.
Data Set N. Examples N. Attributes housing 506 13 (13C) servo 167 4 (4D) auto-mpg 398 7 (4C+3D) machine 209 6 (6D)Table 3- The used data sets (C - continuous attribute; D - discrete attribute).
RECLA system was coupled with C4.5 (a decision tree learner), CN2 (a rule-based system) and Discrim (a linear discriminant). MAE and MAPE were used as regression accuracy measures. The error estimates presented in Table 4 are obtained by a 5-fold cross validation test[3]. We also include the standard deviation of the estimates and the discretization methodology chosen by RECLA.
Table
4 - Best results of Classification algorithms using RECLA.
The observed variability of the chosen discretization method provides an empirical justification for our search-based approach. We can also notice that the best method is dependent not only on the domain but also on the used induction tool (and less frequently on the error statistic). This justifies the use of a wrapper approach that chooses the best number of intervals taking these factors into account.
In another set of experiments we have omitted the use of misclassification costs. This lead to a significant drop on regression accuracy in most of the setups thus providing empirical evidence of the value of adding misclassification costs. However, it should be mentioned that misclassification costs cannot be used with all classification systems. In effect, if the system is not able to output class probability distributions when classifying unseen instances, we are not able to use misclassification costs. The consequence will probably be a lower accuracy as our experiments indicate.
RECLA provides means of using different types of classification systems in regression tasks. The regression models obtained by this methodological approach are in a way more comprehensible to the user as the predictions have higher granularity. However, the loss of detail due to the abstraction of continuous values into intervals has some consequences on regression accuracy. We have tried to find out this effect by obtaining the results of some "pure" regression tools on the same data sets using the same experimental methodology. Table 5 shows the results obtained by a regression tree similar to CART (Breiman et al., 1984), a 3-nearest neighbor algorithm (Fix & Hodges, 1951) and a standard linear regression method :
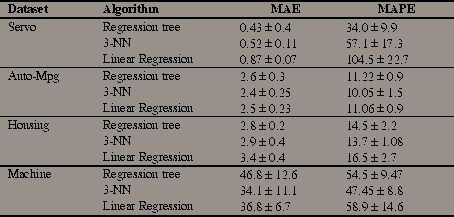
Table
5 - Performance of Regression Tools.
These results are comparable with the ones given in Table 4. This means that our approach can provide an interesting alternative when a different trade-off between accuracy and comprehensibility is needed.